From Prose to Portraits: Mechanism of Sketch Synthesis

SVGCraft employs an LLM as a layout generator to create layouts with "background prompt", "grounding object" and their corresponding bounding boxes, generating masked latents for each box with controlled attention for accurate object placement.
These latents are fused to initialize the SVG canvas and used by a diffusion U-Net for coherent image generation \( \mathcal{I}_m \) that aligns with the layout. The final canvas is obtained via maximizing its similarity between \( \mathcal{I}_r \) and \( \mathcal{R}_d (\theta) \) using LPIPS loss and opacity control.
This opacity control aims to replicate the iterative approach of traditional human sketching by starting with a low opacity value for the Bezier curves. The system then increases the opacity of certain strokes based on relevance and significance provided by the semantic guidance through a loss function \( \mathcal{L}_{sop} \) as defined in \( \mathcal{L}_\text{sop} = \left|1 - \dfrac{\max(A_s \odot \mathcal{R}_d(\theta))}{\max(A_s \odot \mathcal{I}_r)}\right| \). The system updates the opacity value of primitives in each backward pass through gradient descent to mirror the artistic method of intensifying strokes. The final optimization has been defined in the following equation:
This opacity control aims to replicate the iterative approach of traditional human sketching by starting with a low opacity value for the Bezier curves. The system then increases the opacity of certain strokes based on relevance and significance provided by the semantic guidance through a loss function \( \mathcal{L}_{sop} \) as defined in \( \mathcal{L}_\text{sop} = \left|1 - \dfrac{\max(A_s \odot \mathcal{R}_d(\theta))}{\max(A_s \odot \mathcal{I}_r)}\right| \). The system updates the opacity value of primitives in each backward pass through gradient descent to mirror the artistic method of intensifying strokes. The final optimization has been defined in the following equation:
$$\mathcal{L}_\text{synth} = \text{LPIPS}(\mathcal{I}_r, R_d (\theta)) + \lambda_\text{sop} \mathcal{L}_\text{sop}$$
Unraveling Textual Descriptions into Artistic Creations

“In a village[..]” “In a village, a river flows between two men, each standing on opposite banks”

“A car is [..]” “A car is parked on the road beside a river”

“A stop sign [..]” “A stop sign is in grass behind a fence”

“A man and [..]”“A man and a woman stroll in the rain, sharing an umbrella, with the woman holding a bag”

“A dog chasing [..]”“A dog chasing a frisbee on the grass”

“Four bicycles parked [..]”“Four bicycles parked beside a bus”

“Two giraffes and [..]”“Two giraffes and three elephants in a forest”

“A red bicycle [..]”“A red bicycle is at the left of a woman and a blue bicycle towards right of a woman.”
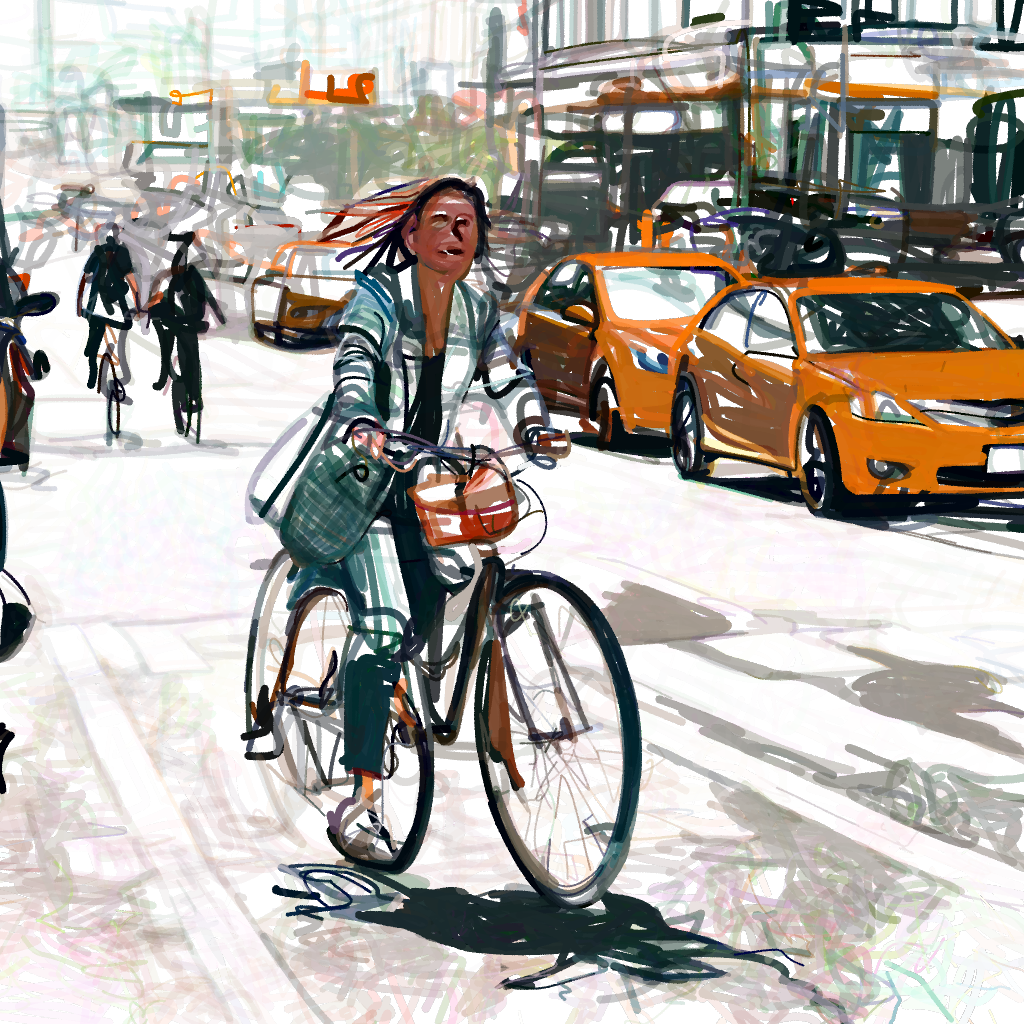
“A woman is [..]”“A woman is riding her bike down the street in front of traffic”

“Batman and Superman [..]”“Batman and Superman in a battle scene, with smoke and explosions in the background.”
From Doodles to Details: Evolution of Sketch Synthesis

Final takeaways
We introduced the notion of SVG synthesis through optimization which reflects the enumeration and spatial relationship between multiple objects described in a text prompt. To this end, we proposed SVGCraft, an architecture that synthesizes free-hand vector graphics via projective transformations of the B\'{e}zier curves or affine transformation of the primitive shapes leveraging novel techniques such as Layout correction, per box mask latent-based canvas initialization, Semantic aware canvas initialization and so on. All these techniques collectively enhance the model efficiency and output quality by replicating the drawing style of a human. Extensive experiments and ablation studies confirm the model's superiority over existing methods, demonstrating its ability to generate aesthetically pleasing and semantically rich SVGs while maintaining their spatial relationship. However, it is unable to draw human faces properly of the supplementary material), which we will address in our future work.
BibTeX
@article{banerjee2024svgcraft,
title={SVGCraft: Beyond Single Object Text-to-SVG Synthesis with Comprehensive Canvas Layout},
author={Banerjee, Ayan and Mathur, Nityanand and Llad{\'o}s, Josep and Pal, Umapada and Dutta, Anjan},
journal={arXiv preprint arXiv:2404.00412},
year={2024}
}